Following the release of Oracle 19c –the long term supported member of the 12c family, many Oracle customers planned to migrate their older DBs especially the widely used version “11g” to the new version. Because of the restrictions on the direct upgrade from 11g to 19c, data pump method became the optimal method for this migration/upgrade.
I’ve run an interesting experiment on testing all the ways to speed up the data pump import on Oracle 19c. The experiment engaged lots of tuning techniques including hidden parameters as well!
To save the reader’s time, I’ll jump into the Experiment result first then I’ll discuss the experiment in details for those who are interested.
Experiment Result:
The following parameter proved to improve the data import time when using impdp:
– Disable the generation of REDO LOG data during the import by using this new impdp parameter:
TRANSFORM=DISABLE_ARCHIVE_LOGGING:Y
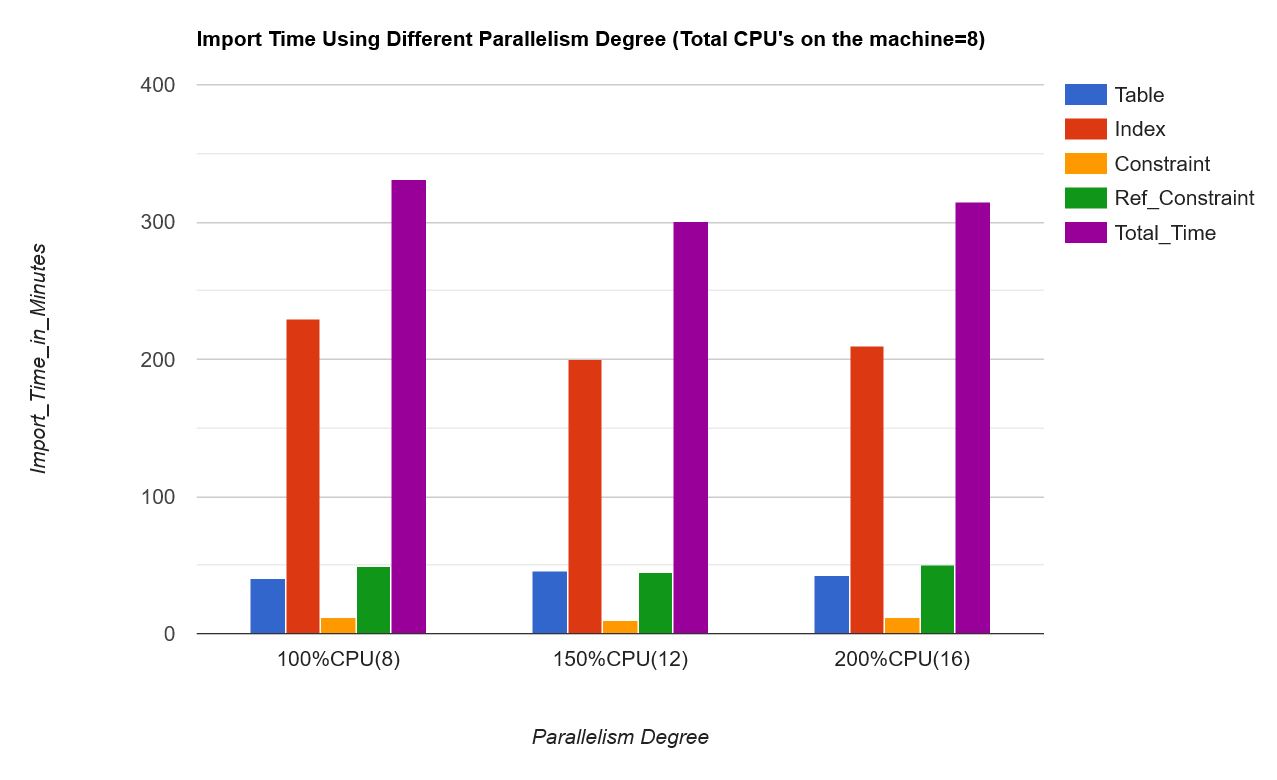
– Set the data pump import parallelism to 150% of the CPU core count on the machine. [This statement may not be accurate for engineered systems]
i.e. if you have 8 CPUs set the parallel parameter to 8 x 1.5 = 12
parallel=12
– Exclude statistics during the import — to be run separately after the import, this will be faster and bug free:
EXCLUDE=STATISTICS
– Disable logical corruption checking [After the import it’s recommended to run the RMAN command: VALIDATE CHECK LOGICAL DATABASE to scan the DB blocks for corruption].
alter system set DB_BLOCK_CHECKING=FALSE;
alter system set DB_BLOCK_CHECKSUM=OFF;
– Switch off the FLASHBACK mode:
alter database flashback off;
– Switch off the ARCHIVELOG mode:
— From mount mode:
alter database noarchivelog;
-Set the DB in NO FORCE LOGGING mode:
alter database no force logging;
– Well sizing the SGA and PGA is crucial for boosting the import operation performance, as per this experiment, unless there are other DBs sharing the same server; the ideal SGA should = 50% while PGA should = 25% of the whole memory in the server.
SQL> alter system set “_dlm_stats_collect”=0 SCOPE=SPFILE;
SQL> alter system set PGA_AGGREGATE_LIMIT=0 SCOPE=BOTH;
The following techniques did NOT have a significant impact on speeding up the data pump import:
– Excluding indexes from the import to create them separately after the import, this method was valid for the legacy imp where no parallelism option was available, but it’s not efficient anymore with impdp. Yes it’s true that impdp will create indexes with no parallelism, but will create multiple indexes at a time based on the parallelism degree. i.e. if setting parallel=8, data pump will create 8 indexes at the same time using no parallel for each index, which is faster than creating the same 8 indexes separately with 8 parallel degree for each one.
– Using manual WORK_AREA_SIZE did NOT add a significant benefit to the import performance, most probably it will slow it down.
– Unless you have a very big memory and very big /dev/shm, don’t create your Temporary tablespace tempfiles under /dev/shm as most probably this will end up forcing the PGA to use the Swap space, slowing down the import process!
– As far you are disabling redo log generation by setting TRANSFORM=DISABLE_ARCHIVE_LOGGING:Y , re-creating the REDO LOG files with bigger block size i.e. 4k didn’t add a significant benefit to the import process.
– Scaling up the following parameters will NOT help with speeding up the import: DB_FILE_MULTIBLOCK_READ_COUNT
_SORT_MULTIBLOCK_READ_COUNT
_DB_FILE_NONCONTIG_MBLOCK_READ_COUNT
_SMM_MAX_SIZE ….. When setting workarea_size_policy=manual
_SMM_PX_MAX_SIZE ….. When setting workarea_size_policy=manual
– Disabling the following parameters did NOT have a significant improvement on the import as well:
_DB_INDEX_BLOCK_CHECKING
_DB_ROW_OVERLAP_CHECKING
_DB_INDEX_BLOCK_CHECKING
_CHECK_BLOCK_AFTER_CHECKSUM
Experiment result is finished, now let’s discuss this experiment in details:
OS: OEL 7.7
CPU: 8 cores / 2.50GHz
RAM: 30 GB
Database size: 863 GB [Tables=523 GB | Indexes=340 GB]
SGA: 15 GB
PGA: 8 GB
Exclude importing statistics: EXCLUDE=STATISTICS
Enable timestamp for each log record: LOGTIME=ALL
ARCHIVELOG modes is disabled: SQL> alter database noarchivelog;
SQL> alter system set DB_BLOCK_CHECKING=FALSE;
SQL> alter system set DB_BLOCK_CHECKSUM=OFF;
SQL> alter system set “_dlm_stats_collect”=0 SCOPE=SPFILE;
SQL> alter system set PGA_AGGREGATE_LIMIT=0 SCOPE=BOTH;

alter system set “_DB_ROW_OVERLAP_CHECKING”=FALSE;
alter system set “_DB_INDEX_BLOCK_CHECKING”=FALSE;
alter system set “_DISABLE_INDEX_BLOCK_PREFETCHING”=TRUE scope=spfile;
alter system set “_CHECK_BLOCK_AFTER_CHECKSUM”=FALSE;
alter system set “_SORT_MULTIBLOCK_READ_COUNT”=16 scope=spfile;
alter system set “_DB_FILE_NONCONTIG_MBLOCK_READ_COUNT”=22 scope=spfile;
alter system set “_smm_max_size”=2147483647 scope=both;
alter system set “_smm_px_max_size”=2147483647 scope=both;
# vi check_physical_logical_corruption.cmd
RUN{
ALLOCATE CHANNEL c1 DEVICE TYPE DISK;
ALLOCATE CHANNEL c2 DEVICE TYPE DISK;
ALLOCATE CHANNEL c3 DEVICE TYPE DISK;
ALLOCATE CHANNEL c4 DEVICE TYPE DISK;
ALLOCATE CHANNEL c5 DEVICE TYPE DISK;
ALLOCATE CHANNEL c6 DEVICE TYPE DISK;
ALLOCATE CHANNEL c7 DEVICE TYPE DISK;
ALLOCATE CHANNEL c8 DEVICE TYPE DISK;
VALIDATE CHECK LOGICAL DATABASE;
}
# nohup rman target / cmdfile=check_physical_logical_corruption.cmd | tee check_physical_logical_corruption.log 2>&1 &
RMAN> select * from v$database_block_corruption;
no rows selected